Model Releases
North Mini Code: El Nuevo Estándar Open-Source para Ingeniería de Software con Cohere
Descubre North Mini Code, el nuevo modelo de razonamiento y generación de código de Cohere que redefine la eficiencia en entornos de desarrollo locales y empresariales.
9 de junio de 2026
Model ReleaseNorth Mini Code
Introducción: Una nueva era para el desarrollo asistido por IA
El ecosistema de la inteligencia artificial aplicada al desarrollo de software ha dado un salto cualitativo este 9 de junio de 2026. Cohere ha lanzado oficialmente North Mini Code, un modelo diseñado específicamente para cerrar la brecha entre la potencia de los modelos masivos en la nube y la agilidad necesaria para el desarrollo local y privado.
A diferencia de otros modelos que intentan ser generalistas, North Mini Code se enfoca en la precisión del razonamiento lógico y la generación de código de alta calidad. Para los ingenieros de software y arquitectos de sistemas, este lanzamiento representa una alternativa robusta y, lo más importante, abierta, para construir pipelines de codificación agéntica sin depender exclusivamente de APIs cerradas y costosas.
- Lanzamiento: 9 de junio de 2026
- Proveedor: Cohere
- Enfoque: Generación de código y razonamiento lógico avanzado
- Licencia: Apache 2.0 (Open Source)
Arquitectura y Características Técnicas
North Mini Code destaca por su arquitectura optimizada. Se trata de un modelo de tipo Mixture-of-Experts (MoE) con un total de 30B de parámetros, pero con una eficiencia sorprendente: solo utiliza 3B de parámetros activos durante la inferencia. Esta característica permite que el modelo mantenga un rendimiento de nivel enterprise mientras reduce drásticamente la latencia y los requisitos de cómputo.
Uno de sus mayores activos es su ventana de contexto. Con un soporte de hasta 256K tokens, los desarrolladores pueden cargar repositorios enteros, documentación técnica extensa o logs complejos para obtener análisis profundos. Además, el modelo permite una salida de hasta 64K tokens, lo que facilita la generación de archivos completos o refactorizaciones extensas en una sola pasada.
Es importante notar que el modelo es estrictamente de texto (text-in, text-out), lo que garantiza un enfoque especializado en la semántica del código y la lógica textual, evitando la sobrecarga de capacidades multimodales que no son críticas para la tarea de programación pura.
- Arquitectura: MoE (Mixture-of-Experts) de 30B parámetros
- Parámetros activos: 3B
- Ventana de contexto: 256K tokens
- Capacidad de salida: Hasta 64K tokens
- Modalidad: Texto a texto únicamente
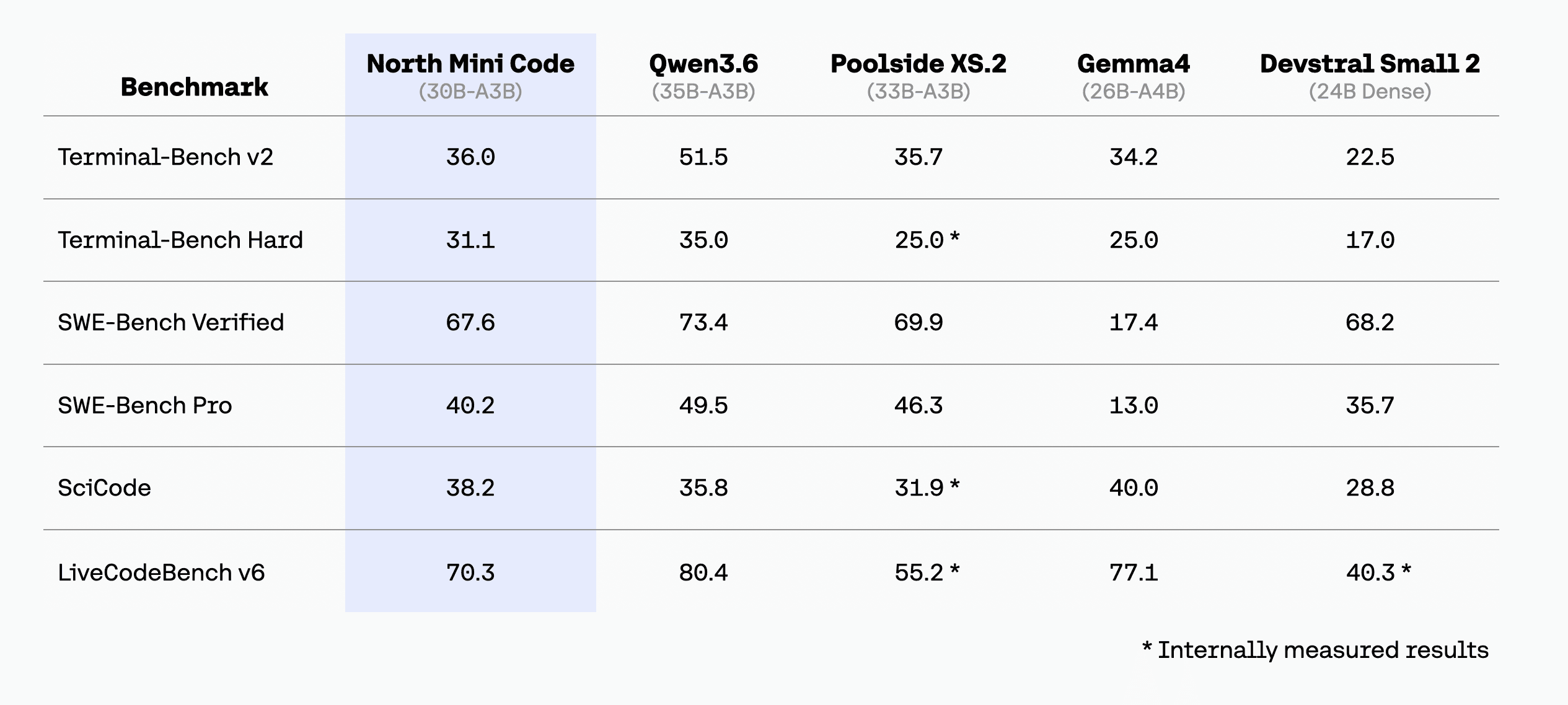
Rendimiento y Benchmarks: Razonamiento de Élite
Los números respaldan la promesa de Cohere. North Mini Code ha demostrado una capacidad de razonamiento excepcional, alcanzando un 75.7% en el benchmark GPQA Diamond, lo que lo posiciona junto a los modelos generalistas de razonamiento más avanzados del mercado actual.