Model Releases
Devstral Small 2 : L'agent de code portable Apache 2.0 de Mistral AI
Mistral AI dévoile Devstral Small 2, un modèle de 24B paramétrés optimisé pour le développement logiciel sous licence Apache 2.0.
9 décembre 2025
Model ReleaseDevstral Small 2
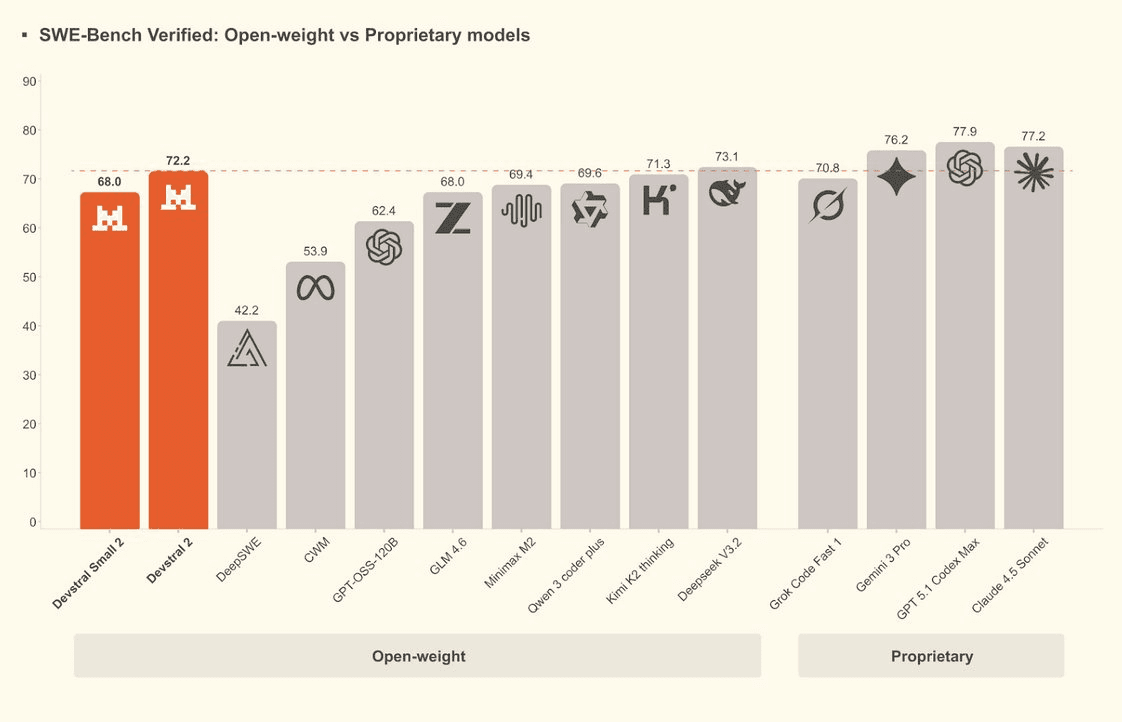
Introduction : Une nouvelle ère pour l'IA Open Source
Mistral AI lance aujourd'hui Devstral Small 2, une évolution majeure de sa gamme de modèles spécialisés dans le développement logiciel. Sorti le 9 décembre 2025, ce modèle succède directement à Devstral Small 1 et tire parti de l'architecture améliorée du Mistral Small 3.1. Dans un paysage où les coûts d'inférence explosent, cette nouvelle version se positionne comme un agent de codage portable, conçu pour être déployé sur des infrastructures locales ou cloud sans sacrifier la performance.
Ce lancement s'inscrit dans la stratégie plus large de Mistral pour démocratiser l'accès aux modèles de pointe via des licences permissives. Contrairement aux modèles fermés qui verrouillent l'usage, Devstral Small 2 offre une flexibilité inégalée pour les ingénieurs souhaitant construire des agents autonomes ou des assistants de code sur mesure. La licence Apache 2.0 garantit que le code et les modèles peuvent être utilisés, modifiés et redistribués librement, favorisant ainsi l'innovation collaborative au sein de la communauté open source.
Pourquoi cela importe-t-il ? Parce que la qualité du code généré par l'IA dépend désormais autant de la précision du modèle que de l'adaptabilité de l'environnement d'exécution. Devstral Small 2 répond à ce besoin en optimisant l'efficacité matérielle tout en maintenant une fenêtre de contexte étendue, permettant de traiter des bases de code entières sans perte de cohérence contextuelle.
- Successor direct de Devstral Small 1
- Architecture dérivée de Mistral Small 3.1
- Licence Apache 2.0 pour usage libre
- Optimisation pour les cas d'usage sensibles aux coûts
Architecture et Fonctionnalités Clés
Devstral Small 2 repose sur une architecture hybride de 24 milliards de paramètres, conçue pour maximiser l'efficacité par rapport à la taille. Le modèle utilise une structure MoE (Mixture of Experts) sophistiquée qui active uniquement les experts pertinents pour chaque tâche de codage. Cette approche réduit la latence et la consommation énergétique tout en améliorant la précision sur les tâches complexes.
L'une des fonctionnalités phares est la capacité multimodale intégrée, permettant au modèle de comprendre non seulement du texte, mais aussi des schémas de code et des visualisations de données. La fenêtre de contexte s'étend à 128k tokens, ce qui est crucial pour le RAG (Retrieval-Augmented Generation) sur de vastes bases de connaissances techniques. Cette capacité permet à l'agent de naviguer dans des dépôts de code massifs sans avoir besoin de résumer manuellement le contexte.
La portabilité est également au cœur de la conception. Le modèle est conçu pour tourner efficacement sur des GPU standards, rendant le déploiement local viable pour les équipes qui privilégient la confidentialité des données. Mistral a également optimisé le format des poids pour faciliter le transfert vers des plateformes de déduction comme Hugging Face ou Ollama.